Eligibility
We’ll identify and reach out to patients who need RPM or CCM and have the coverage to be eligible for reimbursement.
Be more connected to your patients. Connect them to longer, healthier lives.







Managing chronic conditions is an everyday task.
With the 100Plus remote care platform, which includes remote patient monitoring (RPM) and chronic care management (CCM), you have an easy way to stay connected to your patients in between visits. And that makes a difference in your practice — and in the lives of your patients.
Get answers to the most commonly asked questions about remote patient monitoring (RPM) reimbursement, including who pays, what devices are covered and how much is reimbursed.
The care team at Heart South Cardiovascular Group found that some inefficiencies were preventing them from providing patients with the best possible care. In a trial of 100Plus, they found the RPM solution to be highly effective.
Heart South instituted the 100Plus platform across the entire practice and discovered the most significant benefits were operational efficiency, better health outcomes and overall patient care.

“From when we started the program to today, we have seen a decrease in repeat servicing and readmission rates. It has been helpful for keeping patients as healthy as possible.”

“Dealing with blood pressure issues daily, remote patient monitoring really gave us the edge we needed to truly assist our patients.”

More readings don’t have to mean more work. We give you easy-to-access information when and where you need it. Our platform is designed to be easy for you and your patients.
“The 100Plus team helped me implement this without disrupting my practice—we were able to get started right away.”

Reminders, encouragement, recognition—it’s artificial intelligence that creates real connections.

Get notifications, access information, study patterns, and understand your patients—all from one screen.

We’ll manage incoming data and notifications, so you can keep your focus on patient health.

Securely integrate your patient data into electronic health records—create a more complete picture.

Compliance and adherence starts from Day 1—we’ll identify eligible patients and help them get started.
With help and encouragement from Esper, our AI virtual health assistant, RPM patients take their readings more often. More data means more opportunity for intervention, resulting in better health outcomes.
Average decrease in systolic blood pressure for hypertensive patients starting at more than 140 mmHg systolic
Average decrease in diastolic blood pressure for hypertensive patients starting at more than 140 mmHg systolic
Average weight loss for patients who started at more than 286 lbs
Average decrease in blood glucose for diabetic patients

No practitioner likes paperwork. At 100Plus, we make getting reimbursed quicker, easier, and more profitable.
Our services help you deal with the paperwork, increasing your ability to provide better care for patients. By employing technology, you can reach even more patients.
Healthier patients means a healthier practice—and that means being able to help more people live their best lives.
Stay up to date with the latest news, articles and webinars about remote patient monitoring and telehealth.
"*" indicates required fields
You’re busy. Luckily, you don’t need your staff to study incoming data—our team monitors all incoming data, alerting you to what’s important. You and your team can focus on what matters most. It’s how we make RPM accessible to everyone.
Remote care can be complicated. With 100Plus, it’s easy for you, and for your patients. Our platform supports providers and patients at every step.
From identifying eligibility to sending out devices to facilitating reimbursement, we’ve got your back. It’s how practices can thrive and grow while providing the best in patient care.
We’ll identify and reach out to patients who need RPM or CCM and have the coverage to be eligible for reimbursement.

We send the devices to RPM patients. We answer their questions. We set your patients up for success from Day 1.

Our AI virtual health assistant sets schedules, sends reminders, and offers encouragement to make monitoring part of their everyday routine.

We’re here to answer questions about RPM and CCM, providing patients with the information they need to feel comfortable.

Your provider needs you to take readings according to your current care plan, generally daily or as frequently as possible.
You have questions about how our RPM and CCM solutions work. We have answers.
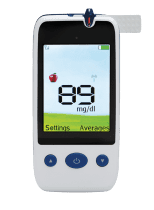
Remote patient monitoring for your healthcare is the best way to give your provider real-time insight into chronic conditions. It’s a safe, secure, and easy way to avoid surprises and set you on the path to better healthcare outcomes.
Our RPM devices only require a cellular connection. There’s no smartphone, no app, and no Wi-Fi needed. That makes it easy for patients to use with nearly any at-home technology. It’s the hardware that makes RPM easy.
You have a network. You know doctors and clinics will benefit from the healthcare outcomes that remote care can provide. You are ready to make connections and build your business.
Our Affiliate Partner Program gives you the freedom to start the conversations with your connections that lead to sales. We’re a trusted partner for people who trust you.
Your talent. Our technology. Together, we can bring remote patient monitoring to everyone.

Have questions about how remote patient monitoring and chronic care management will work for you and your patients? Let’s have a conversation.